Privacidad desde el diseño: Computación segura multi-parte, compartición aditiva de secretos
La analítica de datos es una ciencia que genera información útil derivada de los datos brutos que, en su implementación, permite la utilización de soluciones que cumplan con la protección de datos desde el diseño.

Obstaculizar la investigación con el pretexto de la protección de datos o, por el contrario, justificar la concentración y comunicación masiva de categorías especiales de datos como única forma de llevarla a cabo, es un discurso binario que ya debería estar superado. La analítica de datos es una ciencia que genera información útil derivada de los datos brutos que, en su implementación, permite la utilización de soluciones que cumplan con la protección de datos desde el diseño. Es posible crear espacios de datos federados, que eviten la comunicación y exposición de los datos a terceros, y a la vez proporcionar acceso a la información necesaria a múltiples partes interesadas, optimizando las redes y los procesos, permitiendo, además, implementar políticas controladas de reutilización de datos. Todo ello independientemente de las medidas adicionales de protección de datos desde el diseño y por defecto que se puedan añadir, junto a un modelo de gobernanza, para la garantía de los derechos en los datos de origen.
La cantidad de datos que se recogen actualmente ha aumentado de forma exponencial. Habitualmente estos se encuentran disgregados entre distintas partes (o entidades), dificultando su análisis y explotación para la obtención de conclusiones generales. Una aproximación simplista para resolver este problema es la construcción de grandes repositorios de datos que concentren gran cantidad de ellos en un único punto.
Esta aproximación tiene múltiples problemas. Algunos prácticos: cómo almacenar una cantidad tan masiva y, sobre todo, cómo procesar de forma eficiente todos esos datos, lo que en muchos casos conduce a la paradoja de volver a distribuirlos para poder conseguirlo. Otros son las limitaciones para acceder a esos datos por problemas de confidencialidad, no solo de protección de datos personales, sino relativas a información que puede afectar a secretos comerciales, seguridad de estado, etc. También se encuentra el problema del control del uso secundario de dichos datos, tanto de la perspectiva del RGPD como desde perspectivas comerciales o éticas. Por otro lado, la trazabilidad de la exactitud de dichos datos, que es una cuestión de privacidad, lo es también con relación al mantenimiento de dichas bases de datos y de la calidad de la información inferida. Finalmente, grandes repositorios se tendrían que crear con objetivos distintos, teniendo por consiguiente una gran concentración en uno o varios puntos de gran cantidad de datos, lo que hace de dichos repositorios objetivos más interesantes para los atacantes, se aumentaría la exposición de cara a incidentes y, en el probable caso de una brecha de datos personales, el impacto sería más dañino.
La analítica de datos, necesaria para explotar y extraer resultados de conjuntos de datos, es una ciencia que genera información útil derivada de los dichos datos brutos. Actualmente, las herramientas de analítica de datos permiten la utilización de soluciones de protección de datos desde el diseño, y permiten la creación de espacios federados de datos. Los espacios federados de datos permiten, mediante el empleo de una capa de intermediación ejecutada en las fuentes de datos, la explotación de los mismos, la generación de la información, evitando la comunicación y exposición de los datos a terceros. Estas técnicas permiten que los datos permanezcan en las entidades que los generan, pero permitiendo que se tratan en origen y así proporcionando acceso a la información a una serie de múltiples partes interesadas, optimizando las redes y los procesos. Otra de las grandes ventajas de estos sistemas es poder implementar políticas controladas de reutilización de datos desde el origen, que permiten poder establecer una accountability de los intervinientes y de las operaciones realizadas por el guardián de los datos.
La implementación de la protección de datos desde el diseño se puede realizar utilizando distintas soluciones tecnológicas, como la paralelización y la distribución de proceso en algoritmos basados en aprendizaje automático, el empleo de estrategias de privacidad diferencial, el uso de técnicas criptográficas de enmascaramiento de los datos como son la Computación Segura Multi-parte, el cifrado homomórfico o protocolos de recuperación de información privada PIR (por sus siglas en inglés, Private Information Retrieval), entre otras.
Una de dichas tecnologías habilitadoras es la Computación Segura Multi-parte o SMPC (por sus siglas en inglés, Secure Multiparty Computation). Este es un protocolo criptográfico que, mediante la Compartición Aditiva de Secretos, permite segmentar un dato secreto en distintas partes, de manera que, al compartirse los datos, no pueda ser revelado el dato original por ninguna de las fuentes.
Por ejemplo, si tres compañías desean colaborar para llevar a cabo un estudio del sector al que pertenecen y así beneficiarse conjuntamente de los resultados obtenidos. Sin embargo, condicionantes legales, estratégicos y técnicos imposibilitan esta colaboración.
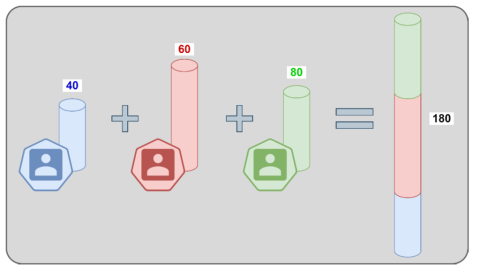
Figura 1: Esquema de suma tradicional en el que todos
los participantes comparten sus datos para la obtención
del resultado final. Cortesía de GMV
Para superarlo, aplicando este protocolo se siguen los siguientes pasos:
Cada participante utiliza su dato para generar aleatoriamente N valores teniendo en cuenta que la suma de los valores generados por cada parte debe ser igual a su valor real. Ejemplo: La entidad con el dato 40 genera aleatoriamente los valores -66, +38 y +68. El resto de entidades hacen lo mismo con sus datos.
Los participantes distribuyen de forma segura todos los valores, pero se guardan uno, el cual mantienen para el próximo paso. Ejemplo (sigue): La entidad anterior comparte los valores +38 con una entidad y +68 con otra, manteniendo el valor -66 sin revelar.
Dentro del entorno privado de cada entidad, se suman los valores recibidos con el no compartido, obteniendo así una suma parcial. Ejemplo (sigue): La entidad anterior recibe del resto de partes los valores +62 y -75 y los suma junto con el valor que mantiene privado (-66). De este modo, obtiene la suma parcial: -66 + 62 -75 = -79.
Todos los participantes comparten de manera segura sus resultados parciales, los cuales se suman para obtener el resultado global. Ejemplo (sigue): La entidad anterior comparte de forma segura su resultado parcial (-79) con los obtenidos por el resto de entidades (+6 y +253). Sumando todos los resultados parciales se conoce el dato global (180) sin que ninguno haya revelado sus propios datos.

Figura 2. Esquema de funcionamiento de la Compartición Aditiva de Secretos para llevar a cabo la suma de los datos de los participantes. Cada entidad segmenta sus datos en tres partes (generadas aleatoriamente), distribuyendo las particiones con el resto de los participantes sin revelar ningún dato. Una vez recibida la información, cada entidad suma las cantidades recibidas, obteniendo un resultado que comparte con el resto. Para finalizar, los resultados obtenidos localmente (los cuales no revelan ninguna información de ninguna de las partes) se comparten y se suman, obteniendo el resultado global, que debe ser idéntico al del esquema tradicional. Cortesía de GMV
En el protocolo se obtiene el resultado deseado sin la necesidad de compartir ningún dato sensible, y el resultado obtenido no sufre ningún tipo de desviación, lo que le diferencia de otro tipo de protocolos como, por ejemplo, la Privacidad Diferencial. Sin embargo, para garantizar la privacidad, es necesario que el número de participantes sea mayor que 2, ya que la Compartición Aditiva de Secretos entre 2 entidades permitiría que cada una de ellas fuese capaz de reconstruir la información privada de la otra.
Finalizar recordando que el sistema perfecto es un ideal que no se corresponde con la realidad. Por ello, incluso con estos sistemas es necesario implementar medidas adicionales de protección de datos desde el diseño y por defecto junto con un modelo de gobernanza para la garantía de los derechos en los datos de origen.
Este post está relacionado con el resto de entradas publicadas anteriormente en el blog de la AEPD relativas a protección de datos desde el diseño y sobre cifrado y privacidad. Se puede encontrar más material en la página de Innovación y Tecnología de la AEPD, en particular:


