Privacy by Design: Secure Multi-Part Computation: Additive Sharing of Secrets

Hindering research under the pretext of data protection or, on the contrary, justifying the concentration and mass communication of special categories of data as the only way to carry it out, is a binary discourse that should already be overcome. Data analytics is a science that generates useful information derived from raw data that, in its implementation, allows the use of solutions that comply with data protection by design. It is possible to create federated data spaces, which avoid the communication and exposure of data to third parties, and at the same time provide access to the necessary information to multiple stakeholders, optimizing networks and processes, allowing, in addition, implement controlled data reuse policies. All this independently of the additional data protection measures by design and by default that can be added, together with a governance model, for the guarantee of rights in the source data.
The amount of data currently collected has increased exponentially. Usually these are disaggregated between different parties (or entities), making it difficult to analyze and exploit them to obtain general conclusions. A simplistic approach to solving this problem is to build large data repositories that concentrate large amounts of data in a single point.
This approach has multiple problems. Some practical, on how to store such a massive amount and, above all, how to efficiently process all that data, which in many cases leads to the paradox of redistributing them in order to achieve it. Others are the limitations to access that data due to confidentiality problems, not only of protection of personal data, but related to information that may affect trade secrets, state security, etc. There is also the problem of controlling the secondary use of such data, both from the perspective of the GDPR and from commercial or ethical perspectives. On the other hand, the traceability of the accuracy of such data, which is a matter of privacy, is also a matter of privacy in relation to the maintenance of such databases and the quality of the information inferred. Finally, large repositories would have to be created with different objectives, thus having a large concentration in one or more points of large amount of data, which makes these repositories more interesting targets for attackers, would increase exposure to incidents and, in the likely case of a personal data breach, the impact would be more harmful.
Data analytics, necessary to exploit and extract results from data sets, is a science that generates useful information derived from such raw data. Currently, data analytics tools allow the use of data protection solutions by design, and allow the creation of federated data spaces. The federated data spaces allow, through the use of an intermediation layer executed in the data sources, the exploitation of the same, the generation of the information, avoiding the communication and exposure of the data to third parties. These techniques allow data to remain in the entities that generate it, but allowing it to be processed at source and thus providing access to information to a number of multiple stakeholders, optimizing networks and processes. Another of the great advantages of these systems is to be able to implement controlled policies of reuse of data from the origin, which allow to establish an "accountability" of the interveners and the operations carried out by the guardian of the data.
The implementation of data protection by design can be done using different technological solutions, such as parallelization and process distribution in algorithms based on machine learning, the use of differential privacy strategies, the use of cryptographic techniques to mask data such as Secure Multiparty Computation, homomorphic encryption or protocols of recovery of Private Information Retrieval (PIR) among others.
One such enabling technology is Secure Multiparty Computation (SMPC). This is a cryptographic protocol that, through additive secret sharing, allows you to segment a secret data into different parts, so that, when the data is shared, the original data cannot be revealed by any of the sources.
For example, if three companies wish to collaborate to carry out a study of the sector to which they belong and thus jointly benefit from the results obtained. However, legal, strategic and technical constraints make this collaboration impossible.
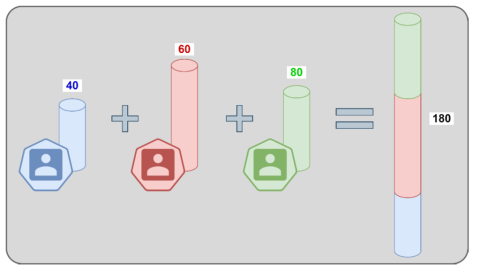
Figure 1: Traditional sum scheme in which all
participants share their data to obtain the
final result. Courtesy of GMV
To overcome it, applying this protocol the following steps are followed:
Each participant uses his data to randomly generate N values taking into account that the sum of the values generated by each party must be equal to their real value. Example: The entity with data 40 randomly generates the values -66, +38, and +68. The rest of the entities do the same with their data.
Participants securely distribute all values, but save one, which they keep for the next step. Example (follows): The above entity shares the values +38 with one entity and +68 with another, keeping the value -66 undisclosed.
Within the private environment of each entity, the values received are added with the non-shared, thus obtaining a partial sum. Example (follows): The previous entity receives from the rest of the parts the values +62 and -75 and adds them together with the value that it keeps private (-66). Thus, you get the partial sum: -66 + 62 -75 = -79.
All participants safely share their partial results, which are added together to obtain the overall result. Example (follows): The previous entity securely shares its partial result (-79) with those obtained by the rest of the entities (+6 and +253). Adding all the partial results is known the global data (180) without any having revealed their own data.

Figure 2. Scheme of operation of the Additive Secret Sharing to carry out the sum of the data of the participants. Each entity segments its data into three parts (randomly generated), distributing the partitions with the rest of the participants without revealing any data. Once the information is received, each entity adds the amounts received, obtaining a result that it shares with the rest. Finally, the results obtained locally (which do not reveal any information of any of the parties) are shared and added, obtaining the overall result, which must be identical to that of the traditional scheme. Courtesy of GMV
In the protocol the desired result is obtained without the need to share any sensitive data, and the result obtained does not suffer any type of deviation, which differentiates it from other types of protocols such as, for example, Differential Privacy. However, to ensure privacy, it is necessary that the number of participants is greater than 2, since the Additive Sharing of Secrets between 2 entities would allow each of them to be able to reconstruct the private information of the other.
End by remembering that the perfect system is an ideal that does not correspond to reality. Therefore, even with these systems it is necessary to implement additional data protection measures by design and by default together with a governance model for the guarantee of rights of the original data.
This post about Secure Multiparty Computation is related to the rest of the previously published entries in the AEPD blog related to ‘data protection by design’ and on ‘encryption and privacy’. Also some more information can be found on the AEPD’s Innovation and Technology website, in particular:
- Guidelines for Data Protection by Default
- Data protection by Default: List of measures (only in Spanish, soon available in English)
- A Guide to Privacy by Design
- Privacy Engineering
- Encryption and Privacy V: The key as personal data
- Encryption and Privacy IV: Zero Knowledge Proofs
- Encryption and Privacy III: Homomorphic encryption
- Encryption and Privacy II: Lifespan of personal data
- Encryption and Privacy: Encryption in the GDPR


