Federated Learning: Artificial Intelligence without compromising privacy
Privacy Enhancing Technologies (PET) enable data sharing by ensuring data protection principles and will also build trust between different actors when sharing data. Federated Learning techniques are a category of PET that allow the development of machine learning systems without the need to communicate personal data between the participants. These techniques can be both Horizontal and Vertical and become a key in the new scenarios that arise for the improvement and development of society, such as Data Spaces.
The data generated by business and individual activity has a great value, which goes beyond the economic. Combining and using data responsibly is essential for disparate matters such as predicting cancer or designing products and services. Due to their great potential, it is necessary to control that they are used for the benefit of society. Maintaining control of the information that can be generated from the data produced by public administrations, companies and citizens is essential to preserve our model of rights and freedoms. Such control is also essential to build trust for entities that have large data repositories, since they will be able to determine who and for what their data is being used, without exposing their commercial and industrial secrets and with technical guarantees that their data will be used for the declared purposes.
Privacy Enhancing Technologies, hereinafter PETs, are a set of computing techniques that allow data to be analysed while maintaining the privacy and the control of them. PETs make it possible to exploit information sustainably and protect fundamental rights, making them essential for economic development. And among PETs strategies and techniques, Federated Learning architectures are included.
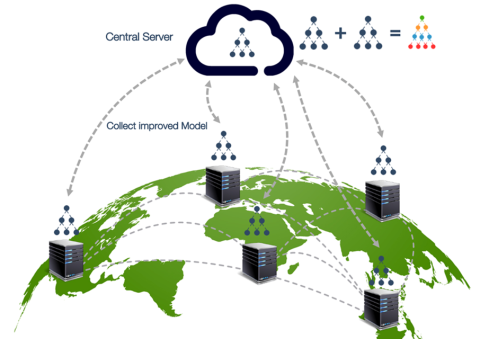
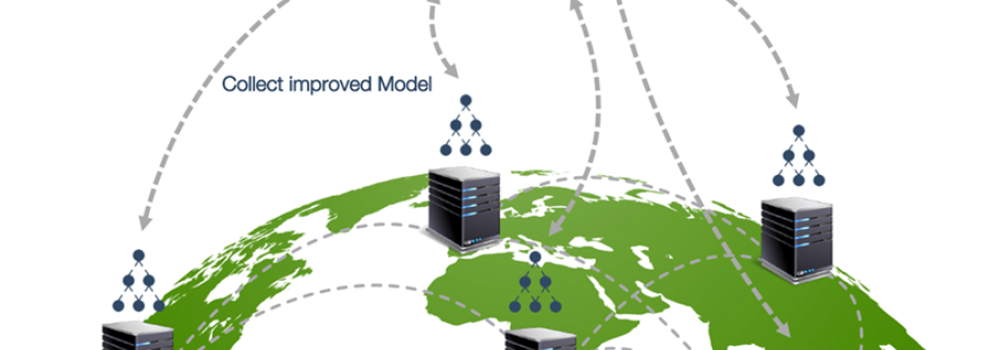
Figure 1: Federated training in which the models are sent to the data silos. Courtesy of Acuratio
Federated Learning enables the creation of machine learning models with a paradigm shift: instead of centralizing the data in a large repository for its analysis, models are sent to the place where the data is located. This strategy, as part of those the "compute-to-data" type, allows a local processing activity to subsequently add the results of the whole partial models developed and consolidate the information obtained from learning in a complete model. In this way, it enables the creation of federated data spaces in which each participant maintains control, sovereignty and preserves data protection, by being able to choose at any moment who can make use of the data and for which use case in particular.
In 2017, the first large-scale tests of Federated Learning began by sending to millions of cell phones an small algorithmic models that learnt from what each user types on their keyboard. The function of these models was to suggest or predict the next word to be written in a chat. The fundamental difference between this technique and what had been done until then, was that private conversations were no longer sent to a central server. In this case, models were sent to the users' devices, providing privacy to users and, at the same time, obtaining much better results than those that existed until then.
This kind of learning falls under the so-called Horizontal Federated Learning and works very well with multiple distributed devices that generate similar data. Conceptually the idea is very simple: let's learn from each device and make an average of the trained models.
However, there are other scenarios in which different entities collect different characteristics of the same individual and it is necessary to put them in common. As an example, we can refer to health care systems where the data that belongs to the same person could be segregated into data silos; i.e., some institutions could store part of the clinical history and others institutions some other specific tests’ results. To teach an algorithm to detect a specific type of cancer through such tests, it would be interesting to combine the different sources of data from the same patient. Vertical Federated Learning can solve this situation -this type of techniques are being intensely studied in Europe as in the USA-.
In order to develop a Vertical Federated Learning model, the first step is to find the patients that different institutions have in common. For not sharing names or any other identifier, techniques based on secure multi-part computing (for example private set intersection) can be used. Then, each entity will have a neural network that will process its data locally -a network that could be provided by a third party-. Using these local neural networks to compute the data, data will be transformed in a way (a representation) that preserves the information that is necessary to obtain. This information is not the original data, so the data subject or data subject cannot be re-identified.
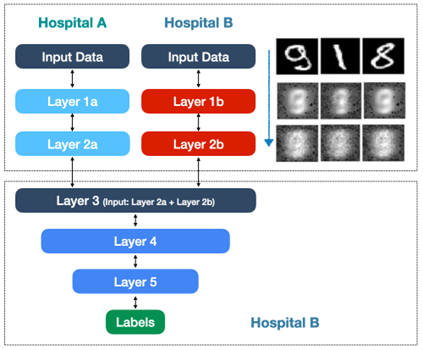
Figure 2: A two-entity model in which the data is anonymized and then the results of the partial models are anonymized and then anonymously aggregated. Courtesy of Acuratio
Then, the outputs of the local networks are grouped anonymously and added into a third neural network that will make the predictions or inferences. This part of the neural network never has access to patient data, it receives data processed by each of the hospitals and computes inferences from them. It is equivalent to the fact that the different networks have developed their own language in which they can communicate but which cannot be understood by an external observer, and it is not possible to re-identify the data subject. The result obtained is identical to what would be obtained with centralized processing.
This Vertical Federated Learning can be complemented with other techniques that can help eliminate bias (“no-peek” techniques), or those like “split learning” techniques that improve the computing capacity or even others like “pooling” that improve the security of the procedure.
In conclusion, the final model of Vertical Federated Learning is composed of multiple elements: the local networks of each entity and the network that makes the predictions. To make any inference it is necessary that the entities collaborate in a coordinated manner, so the correct governance of this infrastructure must be guaranteed. This approach is oriented to processing with neural networks, but alternative techniques are also being developed to make Vertical Federated Learning, such as those based on federated decision trees.
More information about artificial intelligence and data protection from the design is available on the AEPD’s Innovation and Technology webiste. In particular:
- Reference map of personal data processing that embed artificial intelligence
- 10 Misunderstandings about Machine Learning
- Audit Requirements for Personal Data Processing Activities involving AI
- GDPR compliance of processing that embed Artificial Intelligence. An introduction
- A Guide to Privacy by Design
- Post: Privacy by Design: Secure Multi-Part Computation: Additive Sharing of Secrets
- Post: Privacy Engineering
- Post: AI: System vs Processing, Means vs Purposes