AI System: just one algorithm or multiple algorithms?
An Artificial Intelligence system is made up by different elements: interfaces, sensors, communications,… and at least one AI model where is expected to find the AI algorithm. However, the implementation of the AI model into de AI system is more than, for example, a neural network algorithm. Usually, such AI core will be set up by the combination of several algorithms, not just a single one. All those algorithms will have to be assessed regarding the possible impact on the rights and freedoms of the data subjects. Indeed, it should be assessed considering the rest of the elements of the AI system too. The whole assessment should take into account the human intervention in decision making that set up such algorithms, in order to comply with the requirements of transparency and explainability of the AI system.

Image by Gerd Altmann from Pixabay.
An AI system is characterized, among other elements that are making up the system, for the inclusion of an AI core. In the proposal of AIA (EU AI Act regulation) and in other forums is pointed out the importance of the transparency and explainability of the AI systems. In the case of AI models implemented with neural networks and machine learning, it is highlighted the difficulties to do so.
Briefly, a neural network is represented like a net of nodes (or neurons) interconnected. A summary of the way that every node works is that they add the input values and if the result reaches a threshold, it generates one output or another. The node is configured with an offset value and a set of parameters or “weights” linked to every input to the node. A weight is a number used to balance the influence of each input in computation of the node output.
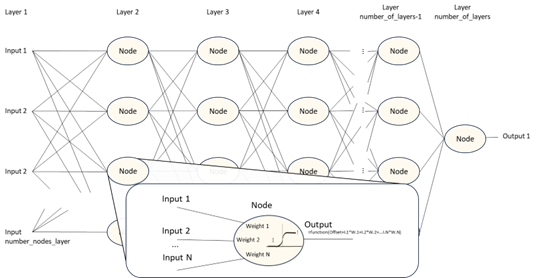
The previous figure has a didactic purpose. A set of nodes doesn’t exist physically. The neural network algorithm could be such simple as the following code:
Intermediate_result = input
For i = 2 to number_of_layers
For j = 1 to number_of_nodes_per_layer
Intermediate_result(j) = activation(intermediate_result,weights(i,j));
Result = intermediate_result;
The previous code could represent a neural network of any size: from one node to millions of nodes, just setting the number of layers and number of nodes per layer. Of course, that code could be more complex for better performance purposes. What makes the difference in the neural network are the weights allocated in the inputs of each node (let’s consider offset included). Neural networks, with the same topology (number of inputs, number of layers, etc.), could carry out completely different tasks depending on the configuration of the weights.
It works because the neural network is a kind of “universal machine”, it means, the neural network could carry out many different tasks depending on the matrix of weights. An analogy could be done with a computer system. A computer is a “universal machine” too, and the task that it executes depends on the program running on it. Of course, the kind of computer could make a difference in the way that a program is running. However, the explanation of the computer structure doesn’t gives enough information about the task and performance of the program running on it. The matrix of weights in a neural network plays the role of a program in a computer. If the weights are changed, the neural network will carry out a different function. In a computer, the programmer writes down the code based in decisions that should be documented. Then, in a neural network moder we should explain how has been set the right matrix of weights.
The matrix of weights in a neural network is not set by a programmer but by an automatic learning process. However, the neural network doesn’t learn by itself, just process the inputs and the weights in every node to get a result. Other algorithms are needed to adjust the matrix of weights. And those algorithms are not usually neural networks algorithms.
The first set of tuning algorithms are those that assess if the behavior of the neural network is good enough regarding some metrics. Let’s name that algorithm the Cost Function Algorithm.
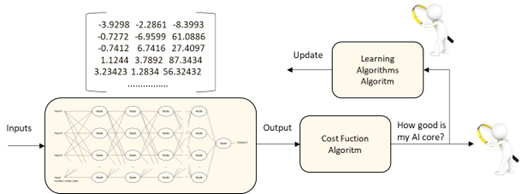
For every input into the neural network, the Cost Function assesses the quality of the resulting output. In the case of supervised training, the result will be assessed regarding a known reference. In the case of unsupervised training, this algorithm could be even more complex.
The training data set is not made of just one input, but a set of inputs instead, and in Machine Learning there must be a huge number of inputs. The results of each single input should carry its own assessment and a conclusion should be obtained from all results. That conclusions states if the neural network is working properly or it is needed to update the matrix of weights.
The Cost Function should perform different tasks: analysis of the result regarding a metric, processing of all partial results to get information about the current performance of neural network and provide information for the learning algorithm. Those all algorithms could be so simple or so complicated. The way the Cost Function algorithm is set up will have an impact in the way the matrix of weights is set up, it means, in the neural network behavior.
Once the Cost Function algorithm reaches the conclusion that the matrix of weights should be updated, the point is how to update that matrix. It is carried out by the Learning Algorithm. This algorithm needs information about how to do such update: some of the information comes from the Cost Function Algorithm, other from the configuration parameters of the Learning Algorithm (learning rate, momentum, dropout, etc.), other should be generated by the own Learning Algorithm, and other depends on the kind of the neural network. Usually, the Learning Algorithm is not a neural network one.
Even more, many Machine Learning systems will use more than a single learning algorithms in the different development phases. For example, the Generative AI use one Learning Algorithm in the pre-training phase, another different one in the Supervised Fine Tuning and another one in the Reinforced Learning from Human Feedback or RLHF, at least.
We cannot forget that the human-in-the loop plays an important role in the execution of such algorithms. In one case, it could depend on a “single” human that we decide the settings of the parameters, the initial weights, and metrics of such algorithms. In other case, it requires the intervention of thousands of people, for example, in the case of the labelling of the input data, or in the case of the RLHF phase of the Generative AI, that will need the rate of as many people as possible. All such people will make decisions that have influence in the final behavior of the AI system, including the probable biases generation.
All the algorithms involved in the learning process will play a more critical role when they are used beyond the development phase. It means, when the AI system is retrained during the operation phase of the AI-system changing dynamically the weights, that is equivalent to change its programming.
This is an educational introduction to this topic. In the real world more factors should be considered. With the same training data set, but different Cost Function algorithm, different Learning Algorithms and human-in-the-loop interventions, the resulting AI system could have a different performance, even to perform different purposes. The conclusion is that the assessment of the neural network and the matrix of weights give so few information about the performance of the neural network. Even, it is needed more than the assessment of the training and verification data, it is necessary to assess the different algorithms involved in the learning process and how they interact, the decisions made to set up the parameters of all such algorithms, and the intervention of the human’s decisions in the learning process. All of them are elements that need explainability.
This post is related with other material released by the AEPD’s Innovation and Technology Division, such us:
• Post Artificial Intelligence: Transparency
• Post Artificial Intelligence: accuracy principle in the processing activity
• Post AI: System vs Processing, Means vs Purposes
• Post Federated Learning: Artificial Intelligence without compromising privacy
• GDPR compliance of processing that embed Artificial Intelligence. An introduction
• Audit Requirements for Personal Data Processing Activities involving AI
• 10 Misunderstandings about Machine Learning
• Reference map of personal data processing that embed artificial intelligence
Related entries

Synthetic data and data protection
Leer más